What if there’s a drug that already exists that could treat a disease with no known therapies, but we just haven’t made the connection? Finding that connection by exhaustively analyzing complex biomechanics within the body — with the help of machine learning, naturally — is the goal of ReviveMed, a new biotech startup out of MIT that just raised $1.5 million in seed funding.
Around the turn of the century, genomics was the big thing. Then, as the power to investigate complex biological processes improved, proteomics became the next frontier. We may have moved on again, this time to the yet more complex field of metabolomics, which is where ReviveMed comes in.
Leila Pirhaji, ReviveMed’s founder and CEO, began work on the topic during her time as a postgrad at MIT. The problem she and her colleagues saw was the immense complexity of interactions between proteins, which are encoded in DNA and RNA, and metabolites, a class of biomolecules with even greater variety. Hidden in these innumerable interactions somewhere are clues to how and why biological processes are going wrong, and perhaps how to address that.
“The interaction of proteins and metabolites tells us exactly what’s happening in the disease,” Pirhaji told me. “But there are over 40,000 metabolites in the human body. DNA and RNA are easy to measure, but metabolites have tremendous diversity in mass. Each one requires its own experiment to detect.”
![]() As you can imagine, the time and money that would be involved in such an extensive battery of testing have made metabolomics difficult to study. But what Pirhaji and her collaborators at MIT decided was that it was similar enough to other “big noisy data set” problems that the nascent approach of machine learning could be effective.
As you can imagine, the time and money that would be involved in such an extensive battery of testing have made metabolomics difficult to study. But what Pirhaji and her collaborators at MIT decided was that it was similar enough to other “big noisy data set” problems that the nascent approach of machine learning could be effective.
“Instead of doing experiments,” Pirhaji said, “why don’t we use AI and our database?” ReviveMed, which she founded along with data scientist Demarcus Briers and biotech veteran Richard Howell, is the embodiment of that proposal.
Pharmaceutical companies and research organizations already have a mess of metabolites masses, known interactions, suspected but unproven effects, and disease states and outcomes. Plenty of experimentation is done, but the results are frustratingly vague owing to the inability to the inability to be sure about the metabolites themselves or what they’re doing. Most experimentation has resulted in partial understanding of a small proportion of known metabolites.
That data isn’t just a few drives’ worth of spreadsheets and charts, either. Not only does the data comprise drug-protein, protein-protein, protein-metabolite, and metabolite-disease interactions, but they’re including data that’s essentially never been analyzed: “We’re looking at metabolites that no one has looked at before.”
The information is sitting in an archive somewhere, gathering dust. “We actually have to go physically pick up the mass spectrometry files,” Pirhaji said. (“They’re huge,” she added.)
Once they got the data all in one place (Pirhaji described it as “a big hairball with millions of interactions,” in a presentation in March), they developed a model to evaluate and characterize everything in it, producing the kind of insights machine learning systems are known for.
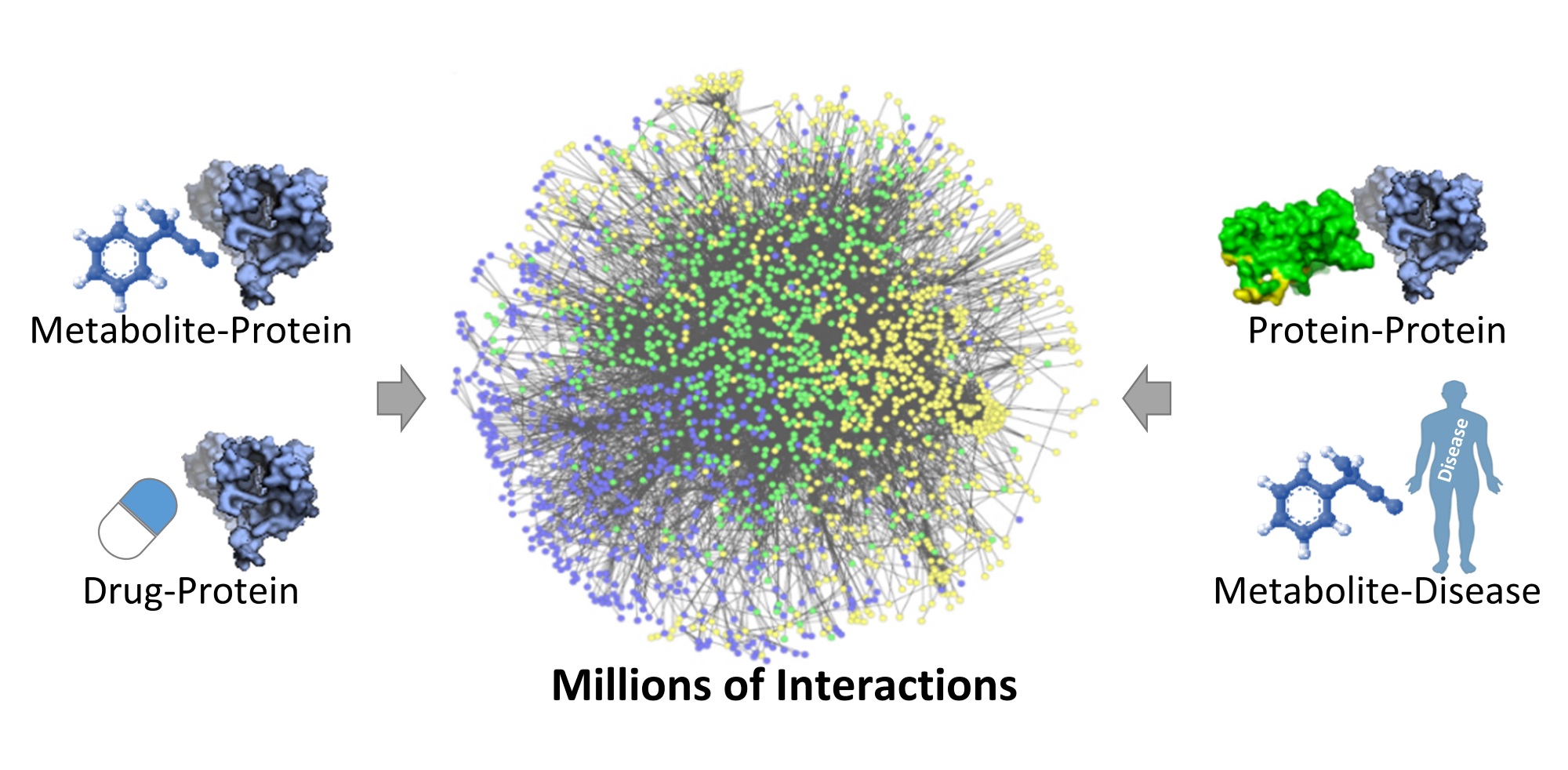
The “hairball.”
The results were more than a little promising. In a trial run, they identified new disease mechanisms for Huntington’s, new therapeutic targets (i.e. biomolecules or processes that could be affected by drugs), and existing drugs that may affect those targets.
The secret sauce, or one ingredient anyway, is the ability to distinguish metabolites with similar masses (sugars or fats with different molecular configurations but the same number and type of atoms, for instance) and correlate those metabolites with both drug and protein effects and disease outcomes. The metabolome fills in the missing piece between disease and drug without any tests establishing it directly.
At that point the drug will, of course, require real-world testing. But although ReviveMed does do some verification on its own, this is when the company would hand back the results to its clients, pharmaceutical companies, which then take the drug and its new effect to market.
In effect, the business model is offering a low-cost, high-reward R&D as a service to pharma, which can hand over reams of data it has no particular use for, potentially resulting in practical applications for drugs that already have millions invested in their testing and manufacture. What wouldn’t Pfizer pay to determine that Robitussin also prevents Alzheimers? That knowledge is worth billions, and ReviveMed is offering a new, powerful way to check for such things with little in the way of new investment.
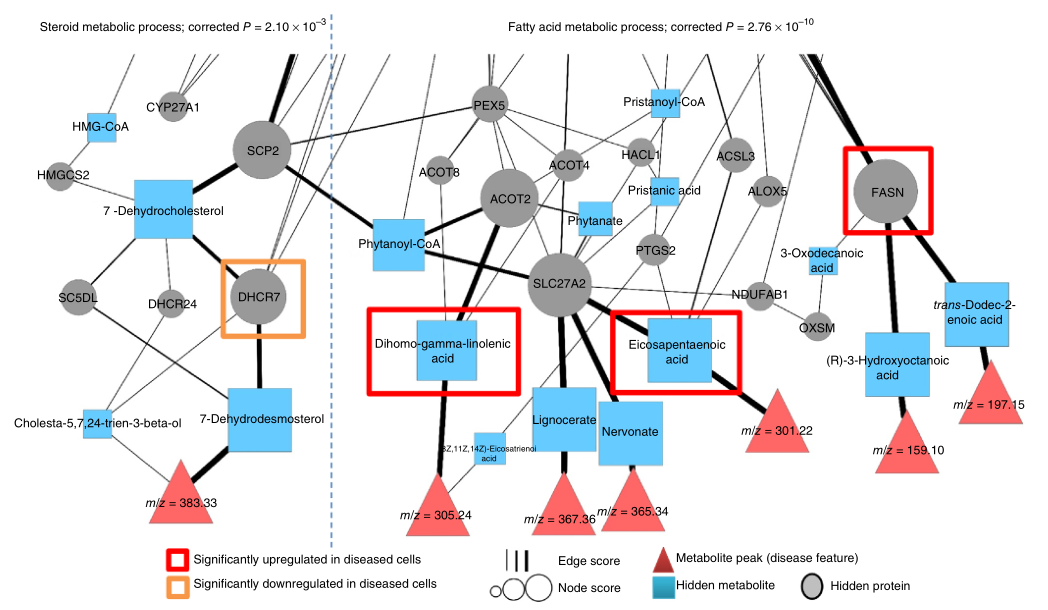
This is the kind of web of molecules and effects that the system sorts through.
ReviveMed, for its part, is being a bit more choosy than that — its focus is on untreatable diseases with a good chance that existing drugs affect them. The first target is fatty liver disease, which affects millions, causing great suffering and cost. And something like Huntington’s, in which genetic triggers and disease effects are known but not the intermediate mechanisms, is also a good candidate for which the company’s models can fill the gap.
The company isn’t reliant on Big Pharma for its data, though. The original training data was all public (though “very fragmented”) and it’s that on which the system is primarily based. “We have a patent on our process for getting this metabolome data and translating it into insights,” Pirhaji notes, although the work they did at MIT is available for anyone to access (it was published in Nature Methods, in case you were wondering).
But compared with genomics and proteomics, not much metabolomic data is public — so although ReviveMed can augment its database with data from clients, its researchers are also conducting hundreds of human tests on their own to improve the model.
The business model is a bit complicated as well — “It’s very case by case,” Pirhaji told me. A research hospital looking to collaborate and share data while sharing any results publicly or as shared intellectual property, for instance, would not be a situation where a lot of cash would change hands. But a top-5 pharma company — two of which ReviveMed already has dealings with — that wants to keep all the results for itself and has limitless coffers would pay a higher cost.
I’m oversimplifying, but you get the idea. In many cases, however, ReviveMed will aim to be a part of any intellectual property it contributes to. And of course the data provided by the clients goes into the model and improves it, which is its own form of payment. So you can see that negotiations might get complicated. But the company already has several revenue-generating pilots in place, so even at this early stage those complications are far from insurmountable.
Lastly there’s the matter of the seed round: $1.5 million, led by Rivas Capital along with TechU, Team Builder Ventures, and WorldQuant. This should allow them to hire the engineers and data scientists they need and expand in other practical ways. Placing well in a recent Google machine learning competition got them $200K worth of cloud computing credit, so that should keep them crunching for a while.
ReviveMed’s approach is a fundamentally modern one that wouldn’t be possible just a few years ago, such is the scale of the data involved. It may prove to be a powerful example of data-driven biotech as lucrative as it is beneficial. Even the early proof-of-concept and pilot work may provide help to millions or save lives — it’s not every day a company is founded that can say that.
from Startups – TechCrunch https://ift.tt/2JWca9t
via IFTTT
No comments:
Post a Comment
Thank You for your Participation