LightTag, a newly launched startup from a former NLP researcher at Citi, has built a “text annotation platform” designed to assist data scientists who need to quickly create training data for their AI systems. It’s a classic picks ‘n’ shovels move, in that the bootstrapped Berlin-based company is hoping to take advantage of the current boom in AI development.
Specifically, LightTag aims to solve one of the main bottlenecks of ‘deep learning’-based AI development: what you get out is only as good as the labeled data you put in. The problem, however, is that labelling data is laborious, and since it’s a job carried out by teams of humans it is prone to inaccuracy and inconsistency. LightTag’s team-based workflow, clever UI, and in-built quality controls is an attempt to mitigate this.
“What I’ve taken from [my previous positions] to LightTag is an understanding that labeled data is more important to success in machine learning than clever algorithms,” says founder Tal Perry. “The difference in a successful machine learning project often boiled down to how well the gathering and use of labeled data was executed and managed. There is a huge gap in the tooling to consistently do that well, that’s why I built LightTag”.
Perry says LightTag’s annotation interface is designed to keep labellers “effective and engaged”. It also employs its own “AI” to learn from previous labelling and make annotation suggestions. The platform also automates the work of managing a project, in terms of assigning tasks to labellers and making sure there is enough overlap and duplication to keep accuracy and consistency high.
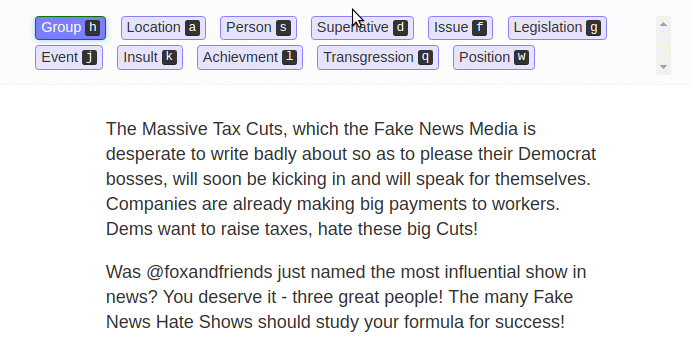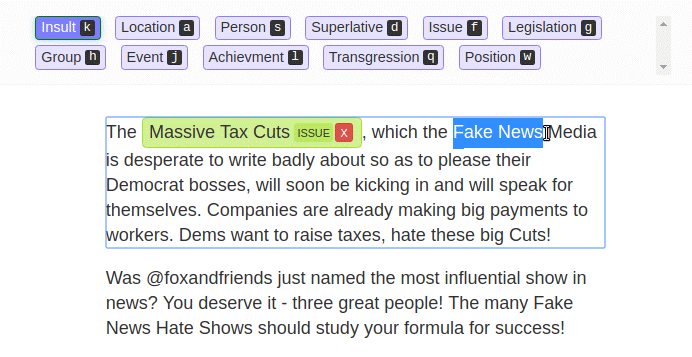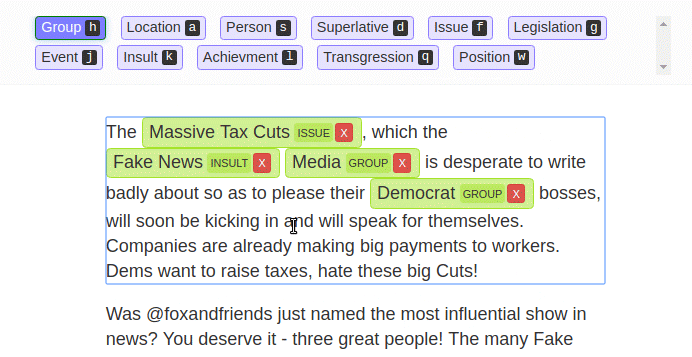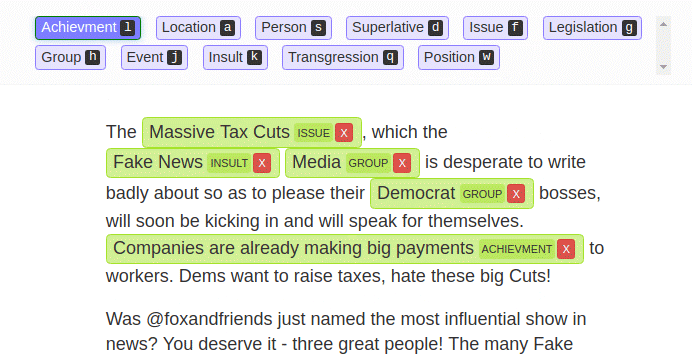
“We’ve made it dead-simple to annotate with a team (sounds obvious, but nothing else makes it easy),” he says. “To make sure the data is good, LightTag automatically assigns work to team members so that there is overlap between them. This allows project managers to measure agreement and recognise problems in their project early on. For example, if a specific annotator is performing worse than others”.
Meanwhile, Perry says acquiring labeled data is one of the silent growth sectors in the recent AI boom, but for many sector-specific industries, such as medical, legal or financial, outsourcing the job is not an option. That’s because the data is often too sensitive, or too specialist for non-subject experts to process. To address this, LightTag offers an on-premise version in addition to SaaS.
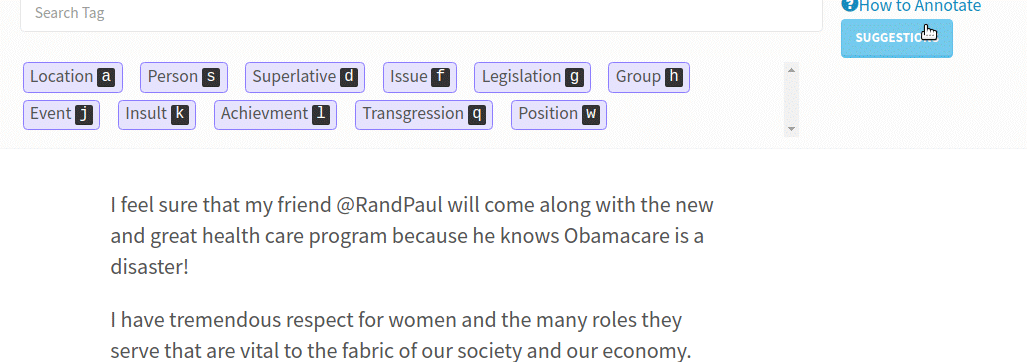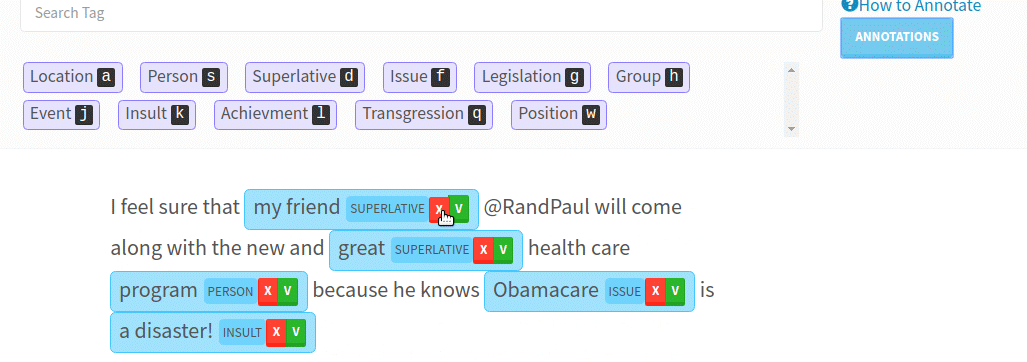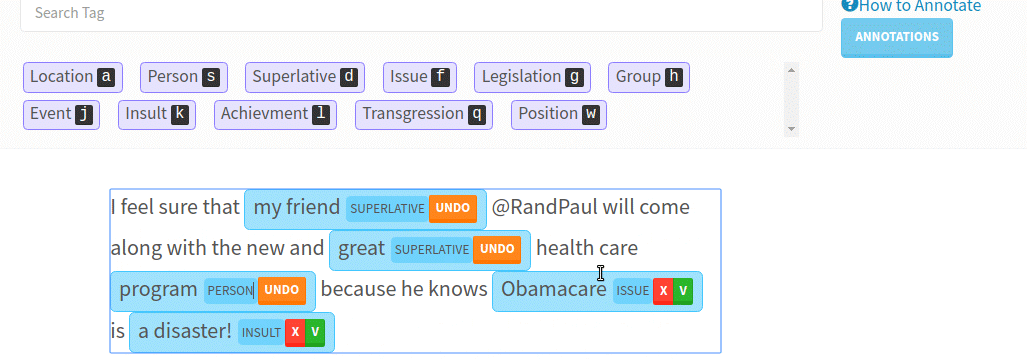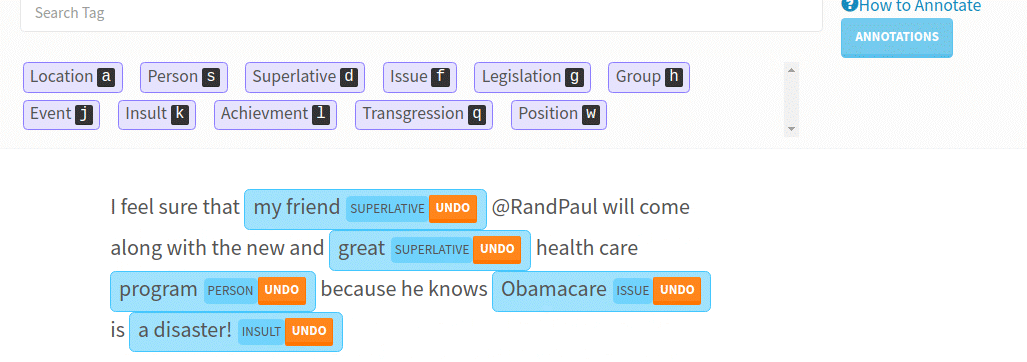
“Every company has huge text datasets that are unstructured (CRM records, call transcripts, emails etc). ‘Deep Learning’ has made it algorithmically feasible to tap that data, but to use Deep Learning we need to train the model with labeled datasets. Most companies can’t outsource labelling on text because the data is too complicated (biology, finance), regulated (CRM records) or both (medical records),” explains the LightTag founder.
Operating in various pilots and in private beta since December 2018, and publicly launched this month, LightTag has already been used by the data science team at a large Silicon Valley tech company that wants its AI to understand free-form text in profiles, as well as by an energy company to analyse logs from oil rigs to predict problems drilling at certain depths. The startup has also done a pilot with a medical imaging company labelling reports associated with MRI scans.
from Startups – TechCrunch https://ift.tt/2rALyTL
via IFTTT
No comments:
Post a Comment
Thank You for your Participation